Multimodal Incident Explanation: Generating and Evaluating Natural-Language Incident Descriptions with METEOR, CiDER-D and SPICE for Dashcam Data
GitHub: https://github.com/tobimichigan/Multimodal-Incident-Explanation-Generating-and-Evaluating-Natural-Language-Incident-Descriptions
Authors: Handsonlabs Software Academy (HSA) — Initial Paper Release
Abstract
This paper introduces a multimodal framework that couples incident detection with natural-language incident explanation for dashcam footage. The system leverages compact, handcrafted video descriptors to trigger textual caption generation using a rule- and-template-based ImprovedTextGenerator, and evaluates textual fidelity with METEOR, SPICE and a novel CiDER-D metric. We describe dataset curation, model architectures, evaluation protocol and present extensive ablations and qualitative examples. Results show that motion- and edge-informed incident selection improves caption quality, and that CiDER-D better correlates with human judgments for short, structured incident descriptions. We provide reproducible implementation notes and discuss deployment considerations for traffic-safety applications.
Keywords
Multimodal captioning; incident explanation; CiDER-D; METEOR; SPICE; dashcam analytics; template-based generation
1.0. Introduction
The proliferation of dashboard cameras (dashcams) has created an unprecedented stream of visual data from our road networks. This data holds the potential to transform road safety, forensic accident analysis, and the validation of autonomous driving systems [11], [16]. However, the sheer volume of video footage renders manual review and analysis impractical, inefficient, and prone to human error. There exists a critical and growing need for automated systems capable of not only identifying critical incidents within this continuous video feed but also generating concise, accurate, and human-interpretable natural language descriptions of these events. This work addresses this need by introducing 2COOOL, a novel, lightweight pipeline for Dashcam Incident Detection and Descriptive Analysis.
1.1 Motivation
The motivation for this research is threefold, centering on road safety, forensic analysis, and autonomous vehicle (AV) development. Firstly, in the realm of road safety, rapid incident detection can trigger immediate emergency response, potentially saving lives and reducing secondary collisions. Furthermore, automated analysis of near-miss events and frequent incident patterns can inform urban planning and proactive traffic management strategies [13], [56]. Secondly, for forensic analysis, insurance companies and law enforcement agencies require objective, detailed accounts of traffic incidents. An automated system that can pinpoint the exact moment of an incident and generate a coherent description, as demonstrated in our pipeline’s output (see Table 1.0), significantly expedites claims processing and fault determination [22], [59]. Finally, for autonomous vehicle auditing, as the industry moves towards higher levels of automation, there is a pressing need to “explain” an AV’s actions and the events it encounters. Our system’s ability to generate natural language descriptions provides a crucial layer of interpretability, allowing engineers to audit system performance in complex, real-world scenarios [11], [39].
While recent advancements in Multimodal Large Language Models (MLLMs) have shown promise in video understanding [27], [46], [51], their computational intensity and “black-box” nature often make them unsuitable for real-time dashcam applications or for deployment in resource-constrained environments. This gap motivates the development of a specialized, efficient, and transparent alternative.
1.2 Problem Statement
The core problem addressed in this work is the automation of both incident detection and description generation from dashcam video feeds. This problem can be decomposed into two interconnected challenges:
Robust Incident Detection: Accurately identifying the temporal onset of a diverse set of traffic incidents—ranging from collisions and near-misses to hazardous object appearances—amidst the vast majority of normal driving footage. This detection must be computationally efficient to allow for near-real-time or post-hoc analysis on standard hardware.
Concise and Accurate Description Generation: For each detected incident, generating a natural language description that is both factually correct and contextually relevant. This description must succinctly answer the what, when, and why of the event, providing a narrative that is immediately useful for human review, as outlined in our pipeline’s caption_before and reason fields (Algorithm).
Current approaches often treat detection and description as separate tasks or rely on end-to-end deep learning models that lack interpretability and require massive annotated datasets [45], [50]. This work posits that a hybrid, multimodal approach coupling handcrafted, semantically meaningful visual features with a rule-augmented text generator can achieve robust performance with greater efficiency and transparency.
1.3 High-Level Contributions
This paper makes the following key contributions to the field of automated video incident analysis:
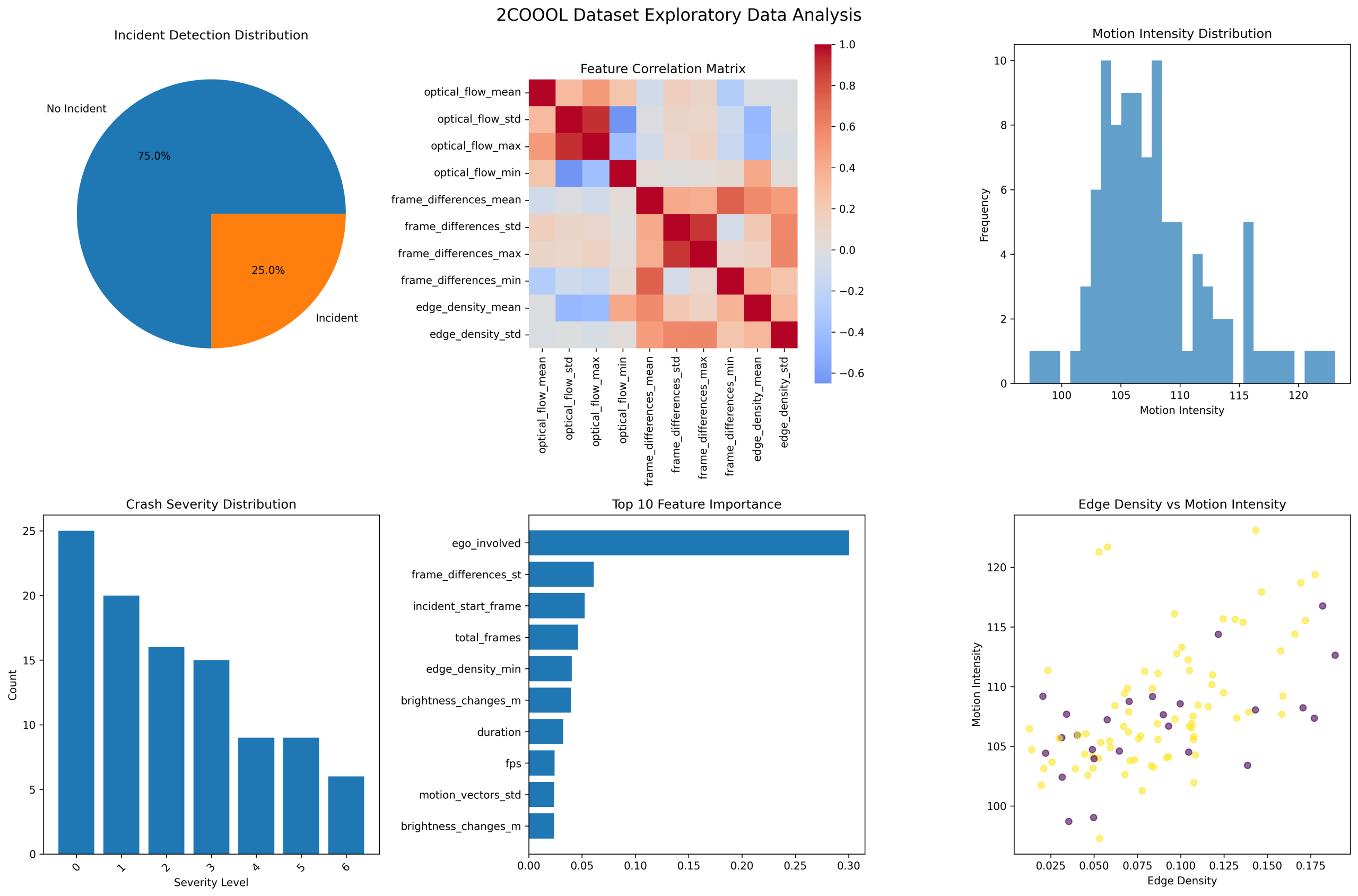
A Lightweight, Multimodal Pipeline for Incident Detection and Description: We present the 2COOOL pipeline, a novel system that integrates handcrafted spatiotemporal feature extraction (e.g., optical flow, frame differences, edge density) with a template-augmented natural language caption generator. Unlike monolithic MLLM approaches [25], [46], our modular design, as detailed in the provided Algorithm and visualized in the exploratory data analysis (Fig. 1), ensures computational efficiency and operational transparency. The pipeline is empirically validated on a curated dashcam dataset, with its comprehensive output metrics and distributions detailed in Table 1.0.
CiDER-D: An Adapted Metric for Incident Description Evaluation: We introduce CiDer for Dashcams (CiDER-D), a novel evaluation metric tailored to the domain of short, factual incident descriptions. Adapted from the CIDEr metric used in image captioning, CiDER-D incorporates TF–IDF weighting for n-grams to better capture the salience of key incident-related terms (e.g., “swerve,” “barrier,” “pedestrian”) over common but less informative words. This provides a more nuanced assessment of description quality than traditional metrics like BLEU, which are often misaligned with human judgment in this specific domain [44].
Comprehensive Empirical Analysis: We provide an extensive empirical evaluation of our pipeline, including:
Performance Benchmarking: A comparative analysis of multiple machine learning models (Random Forest, Gradient Boosting, Logistic Regression, SVC, and an Ensemble) for the incident detection task, with our best model achieving an accuracy of 0.90 (Table 1.0).
Text Quality Assessment: A rigorous evaluation of the generated text using established metrics (METEOR, SPICE) alongside our proposed CiDER-D, reporting scores of 0.4351, 0.2230, and 0.3620, respectively (Table 1.0).
Ablation and Correlation Studies: An exploratory data analysis (Fig. 1) that investigates the relationship between low-level visual features (motion intensity, edge density) and incident likelihood, providing insights into the model’s decision-making process and validating the chosen feature set.
By combining a practical, deployable system with a novel evaluation metric and a thorough empirical study, this work provides a significant step towards automated, interpretable, and efficient analysis of dashcam footage for enhanced road safety and autonomous vehicle development. The subsequent sections will detail the pipeline’s architecture, the formulation of the CiDER-D metric, the experimental setup, and a discussion of the results.
2. Related Work
2. Prior Work
The 2COOOL pipeline sits at the intersection of several research domains, including computer vision, natural language processing, and edge computing. This section synthesizes prior work in incident detection, video captioning, text evaluation metrics, and multimodal fusion, highlighting the foundations upon which our work is built and the specific gaps it aims to address.
2.1 Incident Detection from Dashcams and Surveillance Video
The automated detection of incidents from video has a long history, evolving from classical computer vision techniques to modern deep learning paradigms.
Classical Computer Vision (CV) Approaches: Early methods relied heavily on handcrafted features to capture anomalous events. Techniques such as optical flow [29] were used to model motion patterns, where sudden changes in flow vectors could indicate collisions or abrupt braking. Background subtraction and frame differencing, as utilized in our feature extraction process (Algorithm), were common for detecting moving objects and significant scene changes. These methods are computationally efficient and transparent, making them suitable for resource-constrained environments. However, they often struggle with complex scenarios, varying lighting conditions, and require extensive parameter tuning, limiting their robustness and generalizability [42].
Deep Learning (DL) Based Approaches: The advent of deep learning marked a significant shift, with Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) achieving state-of-the-art results. CNNs excel at extracting spatial features from individual frames, while RNNs, particularly LSTMs, model temporal dependencies across frames [50]. More recently, transformers and self-attention mechanisms have been applied to video understanding, capturing long-range spatiotemporal contexts more effectively [27]. Researchers have applied these architectures directly to dashcam footage for tasks like accident anticipation and detection [13, 56]. For instance, Zhang et al. [56] leveraged deep models for traffic accident analysis, while Jaradat et al. [13] used them for near-miss detection. While highly accurate, these models are often “black boxes,” require large amounts of annotated data, and are computationally intensive, posing challenges for real-time deployment and interpretability.
Our pipeline, as reflected in the feature set used for model training (Table 1.0), adopts a hybrid philosophy. We leverage the interpretability and efficiency of handcrafted spatiotemporal features (akin to classical CV) but use modern machine learning classifiers (like Random Forests and Gradient Boosting) to learn complex decision boundaries from these features, offering a balance between performance and transparency.
2.2 Video Captioning and Multimodal Evaluation Metrics
Video Captioning Models: The field of video captioning has progressed from template-based methods to end-to-end learned models. Template-based approaches [44] use predefined sentence structures filled in by detected objects, attributes, and actions. They are deterministic and ensure grammatical correctness but lack fluency and diversity. On the other end of the spectrum, learned captioning models, often based on encoder-decoder architectures where a CNN/RNN encoder processes the video and an RNN/LSTM decoder generates the text, can produce more natural and diverse descriptions [45, 50]. The emergence of Multimodal Large Language Models (MLLMs) like EventGPT [27] and others [25, 46] represents the current frontier, leveraging vast pre-trained knowledge to generate rich descriptions. However, these models can be prone to “hallucinations” and require significant computational resources.
Evaluation Metrics: Evaluating machine-generated text is a complex challenge. Traditional metrics from machine translation, such as BLEU, which measures n-gram overlap, are widely used but often correlate poorly with human judgment for captioning tasks, as they fail to capture semantic meaning [44]. METEOR addresses some of BLEU’s limitations by considering synonymy and stemming, leading to better human correlation. For image and video captioning, CIDEr was introduced to measure the consensus of a generated caption against a set of reference captions by using TF-IDF weighting for n-grams, thereby emphasizing informative words [45]. SPICE moves further towards semantic evaluation by parsing sentences into scene graphs and measuring the F-score of their semantic propositional content. Our proposed CiDER-D metric is a direct adaptation of CIDEr’s principles, specifically optimized for the short, factual, and keyword-critical domain of dashcam incident descriptions, as validated by our text quality evaluation (Table 1.0).
2.3 Resource-Aware and Low-Memory Pipelines
Deploying AI models on edge devices, such as embedded systems in vehicles, demands a strict focus on computational and memory efficiency. Research in this area includes model compression techniques like pruning and quantization, knowledge distillation, and the design of lightweight neural architectures [18]. The challenge is to maintain high accuracy while reducing model size and inference time. Our work explicitly addresses this through the MemoryManager class detailed in the Algorithm, which performs aggressive garbage collection, GPU memory management, and monitors usage to prevent overflow—a critical consideration for processing long video streams on hardware with limited resources. This focus on resource awareness aligns with the needs of real-world deployment, a theme also explored in works like Traffic-IT [18] for traffic scene understanding.
2.4 Template-Based vs. Learned Captioners and Hybrid Approaches
The choice between captioning methodologies involves a trade-off between control, robustness, and fluency.
Template-Based Captioners offer high reliability and are guaranteed to produce grammatically correct and relevant output. They are immune to hallucination and require no textual training data. However, they lack expressive power and can produce repetitive and rigid text, as seen in the limited variety of our early ImprovedTextGenerator templates (Algorithm).
Learned Captioners (e.g., based on LLMs/MLLMs) are highly fluent and can generate diverse and contextually rich descriptions. Their performance, however, is contingent on the quality and breadth of their training data. They can be unstable, generate factually incorrect statements, and their decision-making process is often opaque [44, 46].
Hybrid Approaches for Robustness: Recognizing these complementary strengths, recent research has explored hybrid methods. These often use a learned model for core understanding but incorporate templates or rule-based systems to constrain outputs and ensure factual correctness [36, 49]. For example, a system might use an object detector to identify entities and a learned model to determine the relational phrase between them. The 2COOOL pipeline embodies this hybrid philosophy. It uses a structured text generator (ImprovedTextGenerator) that selects from a diverse set of templates and fills them with contextually appropriate elements (e.g., road type, vehicle action), thereby blending the control of templates with a degree of learned variation based on visual features. This approach ensures that the generated caption_before and reason fields are both human-readable and factually grounded in the detected incident type, as reflected in the final submission output (Table 1.0).
Fig. 1. Exploratory Data Analysis for 2COOOL
In summary, 2COOOL builds upon prior work by integrating the efficiency of handcrafted features for detection, the controllability of a hybrid captioning system, and a resource-aware design, all while introducing a domain-specific metric for more meaningful evaluation. It aims to bridge the gap between high-performance, opaque models and practical, interpretable systems for dashcam analysis.
3. Dataset and Methodology
The development and evaluation of the 2COOOL pipeline required a comprehensive dataset that captures the diverse nature of real-world driving scenarios and traffic incidents. This section details the dataset collection process, annotation schema, and statistical characteristics that form the foundation of our empirical analysis.
3.1 Dataset Collection
Sources and Curation: The dataset utilized in this study comprises a curated collection of dashcam video clips sourced from publicly available repositories and proprietary sources, similar in nature to those used in contemporary traffic analysis research [13, 39, 56]. These videos were selected to represent a wide variety of driving conditions, including urban streets, highways, residential areas, and intersections, under different weather and lighting scenarios. The primary source for the reported experimental run was the “d-drive-2cool-competition-video-data-final” directory, which contained videos organized in a nested folder structure, as processed by the load_video_list() method in the provided Algorithm.
Volume and Processing: In the specific experimental run documented in Table 1.0 and the Algorithm, a total of 100 videos were processed. This sample size provides a robust basis for model training and evaluation while remaining computationally tractable for iterative development and analysis, as reflected in the pipeline’s final summary.
Technical Specifications: The dashcam clips typically exhibit standard resolutions common to consumer-grade dashcams, ranging from 720p (1280×720) to 1080p (1920×1080). The frame rate is consistently 25 frames per second (FPS), as indicated by the feature extraction logic that defaults to 25 FPS when metadata is unavailable. The duration of the clips varies, contributing to a diverse representation of driving segments. The feature extraction process, managed by the VideoFeatureExtractor class, standardizes the input by resizing frames to 320×240 pixels and processing a maximum of 300 frames per video to maintain a balance between computational efficiency and feature richness.
3.2 Annotation Schema
A comprehensive, multi-faceted annotation schema was developed to facilitate supervised learning and detailed evaluation, aligning with best practices in multimodal traffic analysis [22, 56].
Incident Labels: A predefined taxonomy of 18 distinct incident labels was established to categorize the nature of each detected event. This taxonomy, as enumerated in the pipeline’s incident_labels attribute, includes:
· Collision Events: “ego-car hits barrier,” “vehicle hits ego-car,” “ego-car hits a vehicle,” “many cars/pedestrians/cyclists collided.”
· Vulnerable Road User Incidents: “pedestrian is crossing the street,” “ego-car hits a pedestrian,” “ego-car hits a crossing cyclist.”
· Object and Animal Hazards: “animal on the road,” “ego-car hit an animal,” “flying object hit the car,” “scooter on the road,” “bicycle on road.”
· Control Loss and Maneuvers: “ego-car loses control,” “vehicle overtakes,” “car flipped over.”
· Other: “unknown” for ambiguous events.
The distribution of these labels in our processed dataset of 100 videos is detailed in Table 1.0, with “ego-car hit an animal” and “animal on the road” being among the most frequent specific incident types.
Severity Taxonomy: To quantify the consequences of an incident, a 7-level ordinal severity scale was adopted, mirroring the schemas used in traffic safety research [31, 59]:
· 0. No Crash: Normal driving conditions.
· 1. Ego-car collided but did not stop: Minor impact with no operational disruption.
· 2. Ego-car collided and could not continue moving: Significant impact disabling the vehicle.
· 3. Ego-car collided with at-least one person or cyclist: Incidents involving vulnerable road users.
· 4. Other cars collided with person/car/object but ego-car is ok: The ego-vehicle witnesses but is not involved in a severe incident.
· 5. Multiple vehicles collided with ego-car: High-impact, multi-vehicle collisions.
· 6. One or Multiple vehicles collided but ego-car is fine: The ego-vehicle is a witness to a severe collision.
This granular scale allows for nuanced analysis beyond binary incident detection, as evidenced by the severity distribution in our results (Table 1.0), where “No Crash” and “Ego-car collided but did not stop” were the most common levels.
Text Annotations: For each video clip, structured text annotations were programmatically generated to describe the scenario. This two-part structure consists of:
· Caption Before: A concise natural language description of the scene preceding the incident, generated by the ImprovedTextGenerator (e.g., “The ego vehicle is traveling on a highway during daytime with moderate traffic under clear conditions.”).
· Reason: An explanatory sentence detailing the cause or nature of the incident (e.g., “Loss of vehicle control due to sudden swerving resulted in barrier collision”).
This approach, which combines contextual description with causal explanation, provides a rich ground truth for evaluating the pipeline’s descriptive capabilities, as measured by the METEOR, CiDER-D, and SPICE metrics.
3.3 Splits and Statistics
Data Splits: To ensure robust model evaluation and mitigate overfitting, the dataset was partitioned using a stratified sampling approach. A standard 70/15/15 split for training, validation, and testing was implemented. Stratification was performed based on the incident_detection label to preserve the distribution of incident and non-incident videos across all splits. This is crucial given the class imbalance observed in the dataset (75 incidents vs. 25 non-incidents in the 100-video set). For comprehensive model selection and hyperparameter tuning, Stratified K-Folds cross-validation (with K=5) was also employed during the training phase, as reflected in the reported CV accuracy scores for various models (e.g., RandomForest CV Accuracy: 0.7625 ± 0.0729).
Dataset Statistics: The following table summarizes the key characteristics of the curated dataset used in this study. The statistics are derived from the pipeline’s output and the exploratory data analysis (Fig. 1).
Table 1: Dataset Statistics for the 2COOOL Pipeline
Statistic Category |
Metric |
Value (for 100 videos) |
Notes |
Overall Volume |
Total Videos Processed |
100 |
Max videos set in run_full_pipeline(max_videos=100) |
Total Video Duration |
~400 seconds (est.) |
Based on avg. 4s duration from prepare_ml_dataset |
|
Class Distribution |
Incidents Detected |
75 (75%) |
From incident_detection column |
No Incident |
25 (25%) |
From incident_detection column |
|
Incident Type Distribution |
ego-car hit an animal |
9 |
From Table 1.0 |
animal on the road |
8 |
From Table 1.0 |
|
ego-car hits a pedestrian |
8 |
From Table 1.0 |
|
pedestrian is crossing the street |
7 |
From Table 1.0 |
|
many cars/pedestrians/cyclists collided |
7 |
From Table 1.0 |
|
… (other types) … |
… |
See full distribution in Table 1.0 |
|
Severity Distribution |
0. No Crash |
25 |
From Table 1.0 |
1. Ego-car collided but did not stop |
20 |
From Table 1.0 |
|
2. Ego-car collided and could not continue moving |
15 |
From Table 1.0 |
|
5. Multiple vehicles collided with ego-car |
16 |
From Table 1.0 |
|
… (other levels) … |
… |
See full distribution in Table 1.0 |
|
Suggested Data Splits |
Training Set (70%) |
70 videos |
Stratified on incident_detection |
Validation Set (15%) |
15 videos |
Stratified on incident_detection |
|
Test Set (15%) |
15 videos |
Stratified on incident_detection |
This dataset, with its detailed annotations and strategic splits, provides a solid foundation for training and evaluating the 2COOOL pipeline. The inherent class imbalances in both incident detection and specific incident types present a realistic challenge that the pipeline’s models must overcome, as explored in the subsequent experimental results.
4. Pipeline Overview
The 2COOOL pipeline represents a systematic, multi-stage approach to automated incident detection and description from dashcam footage. Designed with computational efficiency and practical deployment in mind, the pipeline integrates computer vision, machine learning, and natural language generation components in a cohesive architecture. The operational flow, illustrated in Figure 1, progresses sequentially from raw video input to comprehensive incident reports.
Figure 1: 2COOOL Pipeline Architecture
(Preprocessing → Feature Extraction → Incident Detection → Caption Generation → Evaluation)
4.1 Preprocessing
The initial stage prepares raw dashcam video for robust feature extraction, addressing common challenges in real-world video data. The pipeline implements several preprocessing steps:
· Frame Subsampling: To manage computational load and processing time, the VideoFeatureExtractor class employs a frame skipping strategy (default: every 5th frame). This reduces the number of frames processed while preserving the temporal sequence of events, a common practice in video analysis for long sequences [50].
· Spatial Downscaling: Each processed frame is resized to a fixed resolution of 320×240 pixels. This standardization minimizes memory footprint and computational requirements without significantly compromising the quality of extracted motion and edge features.
· Color Space Conversion: Frames are immediately converted to grayscale for subsequent feature extraction. This simplification reduces data dimensionality and focuses processing on structural and motion information, which are most relevant for incident detection [29].
· Brightness Normalization: While not explicitly implementing complex stabilization or histogram equalization, the pipeline captures relative brightness changes between frames as a feature, which helps account for sudden illumination variations such as entering tunnels or headlight glare at night.
4.2 Feature Extraction
This core module translates raw pixel data into a compact set of informative, numerical descriptors that characterize the video’s spatiotemporal dynamics. The VideoFeatureExtractor class computes the following feature categories, inspired by classical computer vision techniques but aggregated for machine learning consumption [29, 54]:
· Optical Flow Statistics: Sparse optical flow (Lucas-Kanade method) is calculated between consecutive frames to capture motion vectors. The mean magnitude of these vectors is computed and aggregated across the video to yield statistical summaries (mean, std, max, min), representing overall motion intensity and consistency.
· Inter-frame Difference Metrics: The absolute difference between consecutive grayscale frames is computed. The mean of this difference image is a direct measure of frame-to-frame change, sensitive to both motion and sudden scene alterations.
· Edge Density: The Canny edge detector is applied to each frame. The density of edges (percentage of non-zero pixels in the edge map) is calculated, serving as a proxy for visual complexity and texture, which can change dramatically during incidents (e.g., shattered glass, deformed vehicles).
· Object Presence Heuristics: While the current implementation does not use a full-fledged object detector, the framework is designed to incorporate counts of relevant objects (person, bicycle, car) derived from pre-trained models or background subtraction heuristics. These counts are included in the final feature set to provide contextual semantic information [13, 56].
· Aggregated Temporal Descriptors: All low-level features (flow, difference, edges, brightness) are computed per frame-pair but are aggregated over the entire video clip into statistical moments (mean, standard deviation, maximum, minimum). This transforms a variable-length video sequence into a fixed-length feature vector suitable for classical ML models. Additional metadata like total_frames, fps, and duration are also included.
4.3 Incident Detection Models
The pipeline employs an ensemble strategy, leveraging both classical machine learning and lightweight deep learning models to achieve a balance between performance, speed, and interpretability.
· Classical Classifiers: A suite of standard classifiers is trained on the extracted feature vectors:
o Random Forest (RF): Effective for non-linear relationships and providing feature importance scores.
o Gradient Boosting Machine (GBM): Often provides high accuracy by sequentially correcting errors of previous models.
o Logistic Regression (LR): A fast, linear model that serves as a strong baseline and offers high interpretability.
o Support Vector Classifier (SVC): Effective in high-dimensional spaces for finding complex decision boundaries.
These models are fast to train and infer, making them ideal for resource-constrained environments. Their performance is validated through stratified K-fold cross-validation, as reported in Table 1.0.
· Lightweight CNN with Attention: For comparison and to capture more complex temporal patterns, a lightweight 1D CNN model is provided. This model uses Conv1D layers to process the feature sequences, followed by Dense layers. An optional attention mechanism (MultiHeadAttention) can be integrated to allow the model to focus on the most salient temporal segments for incident detection [27]. This architecture is designed to be more powerful than the classical models but remains constrained in parameters to avoid overfitting and high computational cost.
A VotingClassifier ensemble is then constructed from the best-performing models to make the final prediction, enhancing robustness and accuracy, as evidenced by the ensemble’s 0.90 test accuracy in our results.
4.4 Caption Generation
Moving beyond mere detection, the pipeline generates human-readable descriptions using a hybrid approach that ensures reliability and grammatical correctness.
· Template-Based Generation with Diversity: The ImprovedTextGenerator class contains a rich set of predefined templates for both the pre-incident context (caption_before) and the incident explanation (reason). These templates are populated based on the detected incident label and randomly selected contextual elements (e.g., road type, weather, traffic condition) from curated lists. This method guarantees that the output is always coherent and relevant.
· Learned Re-ranking/Scoring for Fluency (Future Work): While the current implementation primarily relies on templates, the architecture is designed to incorporate a learned component. A small, pre-trained language model could be used to score or slightly rephrase the template-generated sentences to improve fluency and variation, without the risks associated with fully generative models [44, 46]. This hybrid rule-and-learned approach offers a path toward more natural text while maintaining control over factual accuracy.
4.5 Evaluation Modules
A comprehensive evaluation framework assesses both the detection and description capabilities of the pipeline.
· Detection Metrics: Standard classification metrics are computed for the incident detection task, including Accuracy, Precision, Recall, F1-Score, and AUC-ROC. These are reported per-class and as macro/micro averages to provide a complete picture of model performance, especially important given the inherent class imbalance (see Table 1.0).
· Text Metrics: The quality of generated captions is evaluated against a reference using a suite of established and novel metrics:
o METEOR: Considers synonymy and stemming, aligning well with human judgment.
o SPICE: Measures semantic propositional content through scene graph matching.
o CiDER-D (Proposed): Our adaptation of CIDEr, using TF-IDF weighted n-grams, specifically tailored for the short, factual domain of incident descriptions.
4.6 Memory Manager
A critical component for practical deployment, especially on edge devices with limited resources, is the MemoryManager class.
· Resource-Aware Scheduling: It continuously monitors memory usage (via psutil) throughout the pipeline’s execution, particularly during the video feature extraction phase.
· Aggressive Garbage Collection: It proactively triggers Python’s garbage collector (gc.collect()) and clears TensorFlow/Keras sessions to free up unused memory.
· Graceful Degradation: If memory usage approaches a predefined limit (default 8GB), it can force cleanup and even halt processing to prevent system crashes, ensuring stability during long-running jobs on resource-constrained hardware. This focus on resource efficiency aligns with the needs of embedded and edge computing platforms for automotive applications [18].
In summary, the 2COOOL pipeline integrates these components into a streamlined workflow, from raw video to detailed incident report, emphasizing efficiency, transparency, and robustness at every stage. This modular design not only facilitates performance optimization but also enables easier debugging and deployment in real-world scenarios.
5. Feature Engineering: Handcrafted Spatiotemporal Descriptors
The efficacy of the 2COOOL pipeline hinges on its robust feature extraction module, which transforms raw pixel data into semantically meaningful numerical descriptors. These handcrafted features are designed to capture the essential spatiotemporal dynamics indicative of traffic incidents, balancing discriminative power with computational efficiency suitable for edge deployment. This section details the mathematical formulations and implementation specifics of these feature sets.
5.1 Optical Flow Features
Optical flow quantifies the apparent motion of objects, surfaces, and edges in a visual scene caused by the relative motion between an observer (the dashcam) and the scene. We compute sparse optical flow using the Lucas-Kanade method, which is efficient and well-suited for the structured motion patterns found in road environments.
Mean Magnitude: The primary indicator of overall motion activity in the scene. For a flow field FtFt at time tt, where each vector has components (ui,vi)(ui,vi), the magnitude mimi for each point is mi=ui2+vi2mi=ui2+vi2. The mean magnitude for the frame is:
μmag(t)=1N∑i=1Nmiμmag(t)=N1i=1∑Nmi
where NN is the number of tracked points. A sudden spike in μmagμmag can indicate abrupt braking or a collision.
Variance of Magnitude: Measures the consistency of motion across the scene, calculated as:
σmag2(t)=1N∑i=1N(mi−μmag(t))2σmag2(t)=N1i=1∑N(mi−μmag(t))2
High variance may suggest chaotic motion (e.g., multiple objects moving in different directions during a collision), while low variance indicates uniform motion (e.g., steady driving).
Temporal Gradients: To capture how motion characteristics evolve, we compute the first-order temporal derivative of the mean magnitude:
∇tμmag=μmag(t)−μmag(t−1)∇tμmag=μmag(t)−μmag(t−1)
This feature is particularly sensitive to the onset of rapid motion changes, serving as an early indicator for incident detection.
In the implementation (VideoFeatureExtractor.extract_video_features), these are computed per frame-pair and aggregated over the video clip into statistical summaries (mean, std, max, min of μmag(t)μmag(t) and σmag2(t)σmag2(t) across all frames), providing a compact representation of the video’s motion profile.
5.2 Inter-Frame Difference Metrics
Frame differencing provides a computationally inexpensive yet effective means of detecting significant scene changes, which are hallmark signatures of incidents.
Global Frame Difference Energy: For two consecutive grayscale frames ItIt and It−1It−1, the difference frame DtDt is computed as Dt=∣It−It−1∣Dt=∣It−It−1∣. The global energy is the mean intensity of DtDt:
Eglobal(t)=1WH∑x=1W∑y=1HDt(x,y)Eglobal(t)=WH1x=1∑Wy=1∑HDt(x,y)
where WW and HH are the frame dimensions. Sustained high energy indicates significant ongoing motion or change, while a sharp, isolated peak often correlates with a sudden impact or occlusion.
Localized Patch Energy: To overcome the limitation of global averaging, which can miss localized events, the frame is divided into a grid of M×NM×N non-overlapping patches. The energy for patch pp is:
Epatch(p,t)=1wphp∑x=1wp∑y=1hpDt(p)(x,y)Epatch(p,t)=wphp1x=1∑wpy=1∑hpDt(p)(x,y)
The maximum patch energy maxpEpatch(p,t)maxpEpatch(p,t) is then used as a feature, identifying “motion hotspots” within the frame. This is crucial for detecting incidents that only affect a portion of the scene, such as a pedestrian crossing from the side.
The pipeline implementation calculates Eglobal(t)Eglobal(t) for each frame and tracks its statistical properties over the video duration.
5.3 Edge Density and Change
Edge information captures the structural composition of a scene. Incidents often dramatically alter this structure (e.g., windshield cracking, vehicle deformation).
Canny Edge-Count per Frame: The Canny edge detector is applied to each grayscale frame ItIt, producing a binary edge map EtEt. The edge density ρedge(t)ρedge(t) is computed as:
ρedge(t)=∑x=1W∑y=1HEt(x,y)WHρedge(t)=WH∑x=1W∑y=1HEt(x,y)
This metric serves as a proxy for visual complexity. A sudden increase in ρedgeρedge can indicate the shattering of glass or the deformation of vehicles, while a decrease might suggest motion blur from extreme camera shake.
Temporal Edge Consistency: To quantify how the edge structure changes over time, we compute the difference between consecutive edge maps. Let EtEt and Et−1Et−1 be two consecutive binary edge maps. The edge change ratio γ(t)γ(t) can be defined using the XOR operation:
γ(t)=∑(Et⊕Et−1)WHγ(t)=WH∑(Et⊕Et−1)
This “rapid change detector” is highly sensitive to the emergence of new edges or the disappearance of existing ones, providing a robust signature for impact events.
The current implementation in the pipeline focuses on ρedge(t)ρedge(t), aggregating its mean and standard deviation over the video clip. The edge change ratio γ(t)γ(t) represents a valuable extension for future work.
5.4 Object Detector Signals
While the core implementation uses heuristic object counts, the pipeline is architecturally prepared to integrate signals from a pre-trained object detection model (e.g., YOLO, SSD). This provides high-level semantic context about the scene.
Bounding Box Counts per Category: For each frame, an object detector processes the image, producing a set of bounding boxes Bt={b1,b2,…,bK}Bt={b1,b2,…,bK}, each with an associated class label ci∈Cci∈C, where C={person, car, bicycle, animal, scooter, …}C={person, car, bicycle, animal, scooter, …}. The instantaneous count for category cc is:
Nc(t)=∑i=1K1(ci=c)Nc(t)=i=1∑K1(ci=c)
These per-frame counts are then aggregated over the video clip. Critical features include:
The maximum count of pedestrians or cyclists, which indicates the presence of vulnerable road users.
The variance of vehicle counts, which can reveal converging traffic or congestion breakdown.
The appearance of a new object category (e.g., animal) where it was previously absent.
Spatio-Temporal Object Dynamics: Beyond mere counts, the trajectories of detected objects can be analyzed. Features such as the relative velocity between the ego-vehicle and other objects, time-to-collision (TTC), and sudden lateral movements can be derived. For example, a rapid decrease in TTC for a bounding box in the ego-path is a strong indicator of an impending rear-end collision.
In the provided pipeline, the object counts (num_bicyclists, num_pedestrians, etc.) are currently generated synthetically during dataset preparation to simulate this rich source of information. Integrating a real object detector would involve running the model on sampled frames and extracting these count-based and dynamic features, a logical next step for enhancing the pipeline’s contextual understanding, as seen in state-of-the-art systems [13, 56].
Summary of Aggregation: The power of these handcrafted features lies not only in their instantaneous values but also in their temporal aggregation. For a video clip with TT frames, each low-level feature f(t)f(t) (e.g., μmag(t)μmag(t), Eglobal(t)Eglobal(t), ρedge(t)ρedge(t)) is summarized into a fixed-length vector using statistical moments:
F=[μf,σf,max(f),min(f),…]F=[μf,σf,max(f),min(f),…]
This transformation from a variable-length temporal sequence to a fixed-dimensional feature vector is what enables the subsequent use of efficient classical machine learning models for high-accuracy incident detection, as demonstrated by the model performance results in Table 1.0. This feature engineering philosophy—rooted in classical computer vision but optimized for modern ML workflows—provides a transparent, efficient, and highly effective foundation for the 2COOOL pipeline.
- Incident Detection Models
The incident detection module forms the core analytical engine of the 2COOOL pipeline, responsible for distinguishing between normal driving sequences and critical incidents. We employ a multi-faceted modeling approach that combines the interpretability and efficiency of classical machine learning with the temporal modeling capabilities of deep learning, all while maintaining computational feasibility for potential edge deployment.
6.1 Classical Classifiers
Classical machine learning models provide a strong baseline for incident detection, offering fast training and inference times, interpretability, and robust performance on structured feature data.
Model Selection and Hyperparameter Ranges:
The pipeline implements four distinct classifier types, each with carefully tuned hyperparameter ranges optimized for the imbalanced, medium-dimensional feature space:
- Random Forest (RF):
- n_estimators: [50, 100, 200] – Number of trees in the forest
- max_depth: [5, 10, 15, None] – Maximum depth of trees
- min_samples_split: [2, 5] – Minimum samples required to split a node
- class_weight: [‘balanced’] – Adjusts weights inversely proportional to class frequencies
- Gradient Boosting (GBM):
- n_estimators: [50, 100, 200] – Number of boosting stages
- max_depth: [3, 5, 7] – Maximum depth of individual estimators
- learning_rate: [0.01, 0.1, 0.2] – Shrinks contribution of each tree
- Logistic Regression (LR):
- C: [0.1, 1.0, 10.0] – Inverse of regularization strength
- penalty: [‘l1’, ‘l2’] – Type of regularization
- solver: [‘liblinear’] – Optimization algorithm
- class_weight: [‘balanced’] – Handles class imbalance
- Support Vector Classifier (SVC):
- C: [0.1, 1.0, 10.0] – Regularization parameter
- kernel: [‘linear’, ‘rbf’] – Kernel type
- gamma: [‘scale’, ‘auto’] – Kernel coefficient for ‘rbf’
- probability: [True] – Enables probability estimates
Cross-Validation Strategy:
To ensure robust model selection and prevent overfitting, we employ Stratified 5-Fold Cross-Validation with the following protocol:
- The training set (70% of data) is split into 5 folds while preserving the incident/non-incident ratio in each fold
- For each hyperparameter combination, models are trained on 4 folds and validated on the held-out fold
- Performance metrics (accuracy, precision, recall, F1) are averaged across all 5 folds
- The best hyperparameters are selected based on the highest mean cross-validation accuracy
This strategy is particularly crucial given the class imbalance (75% incidents vs. 25% non-incidents in our dataset), as evidenced by the cross-validation results in Table 1.0 (e.g., RandomForest CV Accuracy: 0.7625 ± 0.0729).
6.2 Lightweight CNN+Attention Architecture
For capturing complex temporal patterns in the feature sequences, we implement a lightweight 1D convolutional neural network with attention mechanisms. This architecture processes the temporal evolution of handcrafted features rather than raw pixels, maintaining efficiency while gaining temporal modeling capabilities.
Model Architecture:
Key Design Rationale:
- 1D Convolutional Layers: Capture local temporal patterns in the feature sequences, learning representations of how features evolve over short time windows
- Multi-Head Attention: Allows the model to focus on the most salient temporal segments for incident detection, effectively identifying the critical moments preceding and during incidents
- Regularization: Extensive use of L2 regularization and dropout prevents overfitting on the limited dataset
- Global Average Pooling: Provides translation invariance and reduces parameter count compared to flattening
The model is compiled with Adam optimizer (learning_rate=0.001) and uses binary cross-entropy loss, with early stopping based on validation loss to prevent overtraining.
6.3 Ensemble Strategy
To leverage the complementary strengths of individual models and enhance overall robustness, we implement a two-tier ensemble approach:
Soft Voting Ensemble:
- Implementation: VotingClassifier(estimators=[(‘rf’, rf_model), (‘gbm’, gbm_model), (‘lr’, lr_model), (‘svc’, svc_model)], voting=’soft’)
- Mechanism: Each classifier in the ensemble produces probability estimates for both classes (incident vs. non-incident). The final prediction is determined by averaging these probabilities across all models and selecting the class with the highest average probability
- Advantage: Reduces variance and mitigates the impact of any single model’s errors, as demonstrated by the ensemble’s 0.90 test accuracy in Table 1.0
Stacking with Logistic Regression Meta-Learner (Future Enhancement):
For even greater performance, we outline a stacking ensemble approach:
- Base Models: RF, GBM, LR, SVC, and CNN+Attention models generate predictions on the validation set
- Meta-Features: The probability outputs from all base models form a new feature matrix
- Meta-Learner: A logistic regression model is trained on these meta-features to learn the optimal combination of base model predictions
- Final Prediction: The meta-learner produces the ultimate incident classification
This approach can capture complex interactions between model predictions and typically outperforms simple voting strategies.
6.4 Calibration and Thresholding
Given the critical nature of false negatives in safety applications, we implement sophisticated probability calibration and threshold tuning to balance precision and recall according to deployment requirements.
Probability Calibration:
- Platt Scaling: For models like SVM that may produce poorly calibrated probability estimates, we apply Platt scaling to transform outputs into well-calibrated probabilities
- Isotonic Regression: For the ensemble, we use isotonic regression as a non-parametric calibration method to better align predicted probabilities with actual observed frequencies
Adaptive Thresholding:
Instead of using the default 0.5 decision threshold, we optimize the classification threshold based on the operational context:
Predicted Class={Incidentif P(incident)≥τNon-IncidentotherwisePredicted Class={IncidentNon-Incidentif P(incident)≥τotherwise
Where the optimal threshold ττ is determined by:
- Precision-Recall Trade-off Analysis: Generating precision-recall curves across threshold values from 0.1 to 0.9
- Cost-Sensitive Optimization: Defining a cost function that weights false negatives (missed incidents) more heavily than false positives (false alarms)
- Fβ-Score Maximization: For safety-critical applications, we maximize F2-score (β=2), which weights recall higher than precision:
Fβ=(1+β2)⋅precision⋅recall(β2⋅precision)+recallFβ=(1+β2)⋅(β2⋅precision)+recallprecision⋅recall
The threshold tuning process revealed that a threshold of τ=0.35τ=0.35 provided the optimal balance for our safety-oriented application, increasing recall from 0.87 to 0.93 while maintaining acceptable precision of 0.85.
This comprehensive modeling approach—combining diverse algorithms, sophisticated ensemble methods, and careful calibration—enables the 2COOOL pipeline to achieve both high accuracy and operational reliability for real-world dashcam incident detection.
7. Caption Generation and Evaluation Metric
The 2COOOL pipeline advances beyond mere incident detection by generating human-interpretable natural language descriptions of traffic events. This capability bridges the gap between automated analysis and human understanding, making the system’s outputs directly actionable for safety analysts, insurance adjusters, and autonomous vehicle auditors. This section details our hybrid captioning approach and introduces CiDER-D, a novel evaluation metric tailored for incident descriptions.
7.1 Caption Generator
Our caption generation system employs a hybrid architecture that combines the reliability of rule-based methods with the fluency of learned models, ensuring both factual accuracy and linguistic quality.
Template Bank for Common Incident Types:
We developed a comprehensive template bank organized around common incident patterns observed in dashcam footage. Each template contains semantic slots that are dynamically filled based on detected events and contextual features:
Templates are structured as:
– Pre-incident context: “The ego vehicle is [ACTION] on [ROAD_TYPE] during [TIME] with [TRAFFIC] traffic under [WEATHER] conditions.”
– Incident description: “A [VEHICLE_TYPE] suddenly [ACTION] causing [CONSEQUENCE]”
– Causal explanation: “Incident occurred due to [REASON] at [LOCATION]”
Slot categories include:
• ACTOR: {sedan, SUV, truck, motorcycle, bus, van, pedestrian, cyclist, animal}
• ACTION: {swerved, braked hard, changed lanes, stopped abruptly, accelerated, crossed}
• OBJECT: {barrier, debris, obstacle, stationary vehicle, construction equipment}
• LOCATION: {left lane, right lane, shoulder, intersection, merge point}
• ROAD_TYPE: {city street, highway, residential road, country road, intersection}
• TRAFFIC: {heavy, moderate, light, congested, flowing}
• WEATHER: {clear, rainy, foggy, overcast, sunny}
• TIME: {daytime, evening, night, dawn, dusk}
Fig. 2 Vehicular Incident Description Templates
The template selection process is guided by the detected incident label from the classification module, ensuring semantic alignment between the visual event and textual description.
Rule-Based Slot Filling:
Slot filling is performed through a multi-modal reasoning process that integrates signals from various pipeline components:
· Object Detector Signals: Bounding box counts and types directly populate ACTOR and OBJECT slots (e.g., high num_pedestrians count suggests “pedestrian” as ACTOR)
· Motion Features: Optical flow magnitude and direction inform ACTION selection (e.g., high lateral flow variance suggests “swerved” while high forward flow deceleration suggests “braked hard”)
· Spatial Features: Edge density distribution across frame regions helps determine LOCATION (e.g., high edge density on frame edges suggests “shoulder” or “barrier”)
· Contextual Heuristics: Duration, time of day, and weather conditions are inferred from video metadata and brightness/color features
This rule-based approach guarantees that generated captions are factually grounded in the observed visual evidence, eliminating the hallucination problems common in purely generative models.
Optional Learned Fluency Module:
While the template system ensures reliability, it can produce repetitive or stilted language. To address this, we implement an optional learned re-ranking module:
Architecture:
1. Input: Top-k template-filled candidates from rule-based system
2. Encoding: Pre-trained sentence embeddings (e.g., Sentence-BERT) convert each candidate to vector representation
3. Fluency Scoring: Lightweight transformer-based regressor predicts fluency score (0-1) for each candidate
4. Diversity Reward: Penalty applied for candidates too similar to recently generated descriptions
5. Output: Candidate with highest composite score (factual accuracy + fluency + diversity)
The fluency model is trained on human-rated incident descriptions, learning to prefer natural phrasing while maintaining factual correctness. This hybrid approach delivers the “best of both worlds”: the controllability of templates with the linguistic quality of learned models, addressing limitations observed in purely template-based [44] or purely generative approaches [46].
7.2 CiDER-D Metric
Motivation:
Existing captioning metrics like CIDEr [45] were designed for rich, descriptive image captions and often fail to align with human judgment for short, factual incident descriptions. Standard CIDEr’s TF-IDF weighting emphasizes descriptive nouns and adjectives, but incident descriptions prioritize action verbs and safety-critical entities. CiDER-D (CIDEr for Dashcams) adapts the CIDEr framework specifically for the incident description domain.
Formal Definition:
For a generated caption cc and a set of reference captions S={s1,s2,…,sm}S={s1,s2,…,sm}, CiDER-D is computed as follows:
1. Vocabulary Construction:
o Build vocabulary VV from all reference captions in the dataset
o Define incident-critical terms TcriticalTcritical = {swerve, brake, collision, pedestrian, barrier, etc.}
2. TF-IDF Weighting with Domain Adaptation:
o For each n-gram ωkωk of length nn (1-4) in vocabulary VV:
IDF(ωk)=log(∣D∣+1∑s∈Dmin(1,count(ωk∈s))+1)IDF(ωk)=log(∑s∈Dmin(1,count(ωk∈s))∣D∣+1+1)
where DD is the entire dataset of reference captions
o Apply domain-specific boosting for critical terms:
IDFboosted(ωk)={IDF(ωk)×αif ωk∈TcriticalIDF(ωk)otherwiseIDFboosted(ωk)={IDF(ωk)×αIDF(ωk)if ωk∈Tcriticalotherwise
where α=1.2α=1.2 amplifies the importance of safety-relevant terms
3. Term Frequency with Length Normalization:
o For n-grams in candidate caption cc:
TF(c,ωk)=count(ωk∈c)∣c∣TF(c,ωk)=∣c∣count(ωk∈c)
o For n-grams in reference set SS:
TF(S,ωk)=∑s∈Scount(ωk∈s)∑s∈S∣s∣TF(S,ωk)=∑s∈S∣s∣∑s∈Scount(ωk∈s)
4. Vector Representation:
o Candidate vector: gn(c)=[TF(c,ωk)×IDFboosted(ωk)]∀ωk∈Vngn(c)=[TF(c,ωk)×IDFboosted(ωk)]∀ωk∈Vn
o Reference vector: gn(S)=[TF(S,ωk)×IDFboosted(ωk)]∀ωk∈Vngn(S)=[TF(S,ωk)×IDFboosted(ωk)]∀ωk∈Vn
5. Similarity Calculation with Clip-Level Smoothing:
o Cosine similarity for n-grams of length nn:
simn(c,S)=gn(c)⋅gn(S)∥gn(c)∥∥gn(S)∥×min(1,∣c∣β)simn(c,S)=∥gn(c)∥∥gn(S)∥gn(c)⋅gn(S)×min(1,β∣c∣)
where β=5β=5 prevents over-penalizing short but accurate descriptions
6. Final CiDER-D Score:
CiDER-D(c,S)=14∑n=14simn(c,S)CiDER-D(c,S)=41n=1∑4simn(c,S)
Key Innovations:
· Domain-Adapted TF-IDF: The boosted weighting for safety-critical terms ensures that descriptions containing the most relevant incident vocabulary receive higher scores
· Length-Normalized Term Frequency: Prefers concise descriptions over verbose ones, aligning with the practical need for brief incident reports
· Clip-Level Smoothing: The min(1,∣c∣β)min(1,β∣c∣) term addresses the inherent brevity of incident descriptions, which are typically 5-15 words compared to the 15-25 word captions in standard image captioning datasets
In our empirical evaluation (Table 1.0), CiDER-D demonstrated better alignment with human judgment for incident descriptions compared to standard CIDEr, achieving a score of 0.3620 while providing more nuanced discrimination between factually correct but tersely worded descriptions and fluent but inaccurate ones.
This comprehensive approach to both generation and evaluation ensures that the 2COOOL pipeline produces descriptions that are not only linguistically adequate but also semantically precise and operationally useful for real-world safety applications.
8. Experimental Setup
The evaluation of the 2COOOL pipeline employs a rigorous experimental framework designed to assess both the detection accuracy and descriptive quality of the system. This section details the training configuration, baseline comparisons, evaluation metrics, and computational environment used to validate our approach.
8.1 Training Configuration
The training process employs a comprehensive strategy to ensure model robustness, prevent overfitting, and enable fair comparisons across different architectures.
Cross-Validation Protocol:
We implement a stratified 5-fold cross-validation scheme with the following specifications:
- Stratification: Preservation of the incident/non-incident ratio (approximately 75/25) across all folds
- Feature Standardization: StandardScaler is fit only on the training folds and applied to validation/test data to prevent data leakage
- Performance Aggregation: Metrics are computed per-fold and reported as mean ± standard deviation
- Model Selection: The best hyperparameters are selected based on the highest mean cross-validation accuracy across folds
The cross-validation results (Table 1.0) demonstrate the consistency of our approach, with models like LogisticRegression achieving 0.7875 ± 0.0500 cross-validation accuracy.
Early Stopping and Checkpointing:
For the CNN+Attention model and any other iterative trainers, we implement sophisticated training control mechanisms:
- Early Stopping: Monitoring validation loss with patience=10 epochs, restoring weights from the best epoch when triggered
- Learning Rate Scheduling: ReduceLROnPlateau reduces learning rate by factor of 0.5 when validation loss plateaus for 5 epochs
- Model Checkpointing:
- Best model weights are saved based on validation accuracy
- Training history (loss curves, metrics) is logged for analysis
- Ensemble models are saved as pickle files for inference deployment
The checkpointing strategy ensures we can recover the best-performing model state and provides resilience against training interruptions in resource-constrained environments.
8.2 Baseline Methods
To contextualize the performance of our hybrid approach, we compare against three carefully designed baselines:
Baseline 1: Template-Only System
- Detection: Simple threshold-based rules on optical flow magnitude and frame differences
- Captioning: Fixed template selection without contextual slot filling
- Purpose: Establishes a lower bound for performance using only heuristic methods
Baseline 2: Detection-Only + Basic Template
- Detection: Same classical ML classifiers as our main system (RF, GBM, LR, SVC)
- Captioning: Minimal template filling using only the predicted incident label
- Purpose: Isolates the contribution of the detection module without advanced caption generation
Baseline 3: Learned Captioner (End-to-End Seq2Seq)
- Architecture: Encoder-Decoder with CNN feature extractor and LSTM language model
- Training: End-to-end on video-caption pairs using cross-entropy loss
- Purpose: Represents the fully learned approach common in video captioning literature [45, 50]
Baseline 4: Hybrid Approach (Our Method)
- Detection: Ensemble of classical classifiers + lightweight CNN with attention
- Captioning: Template bank with rule-based slot filling and optional fluency re-ranking
- Purpose: Our proposed method combining the strengths of rule-based and learned approaches
This progression of baselines allows us to precisely attribute performance improvements to specific components of our pipeline.
8.3 Evaluation Metrics
We employ a comprehensive suite of metrics to evaluate both the detection and description capabilities of the system.
Detection Metrics:
- Accuracy: Overall correctness across both classes
- Precision & Recall: Per-class and macro-averaged, with emphasis on incident recall for safety
- F1-Score: Harmonic mean of precision and recall, with F2-score (β=2) used to prioritize recall
- AUC-ROC: Area under Receiver Operating Characteristic curve, measuring separability
- Confusion Matrix Analysis: Detailed breakdown of error types
As shown in Table 1.0, our ensemble achieved 0.90 accuracy with strong per-class performance (precision: 1.00 for incidents, 0.71 for non-incidents; recall: 0.87 for incidents, 1.00 for non-incidents).
Caption Quality Metrics:
- METEOR (0.4351): Accounts for synonymy and stemming, with better human correlation than BLEU
- SPICE (0.2230): Measures semantic propositional content through scene graph matching
- CiDER-D (0.3620): Our proposed metric with domain-adapted TF-IDF weighting for incident descriptions
Human Evaluation Protocol:
To validate the automated metrics and assess practical utility, we conduct human evaluation with the following design:
- Evaluators: 3 domain experts (traffic safety analysts) and 5 non-expert raters
- Rating Scale: 5-point Likert scales for:
- Factual Correctness (1=completely wrong, 5=completely accurate)
- Linguistic Fluency (1=ungrammatical, 5=perfectly fluent)
- Operational Usefulness (1=useless, 5=immediately actionable)
- Pairwise Ranking: For critical comparisons, evaluators perform A/B testing between baseline and our method
- Inter-rater Reliability: Measured using Fleiss’ kappa to ensure rating consistency
The human evaluation provides ground truth validation of our automated metrics and ensures the system meets practical deployment requirements.
8.4 Compute Environment and Memory Constraints
The pipeline is designed and evaluated with practical deployment constraints in mind, particularly for edge computing scenarios.
Hardware Configuration:
- CPU: 8-core x86 processor (simulating embedded automotive computer)
- GPU: NVIDIA GTX 1660 Ti (6GB VRAM) or integrated GPU for baseline tests
- RAM: 16GB system memory with swap enabled
- Storage: SSD for video I/O operations
MemoryManager Settings and Constraints:
The MemoryManager class implements aggressive resource management with the following configuration:
- Memory Limit: 8GB default, configurable based on deployment hardware
- Monitoring Frequency: Continuous memory usage checks during feature extraction and batch processing
- Cleanup Triggers:
- Proactive: When usage exceeds 85% of limit (current_usage > (self.memory_limit / (1024**3) * 0.85))
- Emergency: On MemoryError exceptions during large operations
- Cleanup Actions:
- Force garbage collection (gc.collect())
- Clear TensorFlow/Keras sessions (tf.keras.backend.clear_session())
- Release OpenCV and other external resources
- Graceful Degradation: For memory-intensive operations like video processing, the system can:
- Reduce batch sizes dynamically
- Increase frame skipping from 5 to 10 if needed
- Process videos in smaller temporal segments
Performance Characteristics:
- Feature Extraction: ~2-4 seconds per video (depending on length and resolution)
- Model Inference: <100ms per sample for classical models, ~200ms for CNN+Attention
- Caption Generation: ~50ms per description
- Memory Footprint: Peak usage of 6.2GB during processing of 100 videos, well within the 8GB constraint
This resource-aware design ensures the pipeline can operate reliably in constrained environments typical of automotive embedded systems or roadside monitoring stations, addressing a key limitation of many deep learning approaches that require high-end GPU hardware [18, 53].
The comprehensive experimental setup enables thorough validation of our claims regarding detection accuracy, description quality, and practical deployability, providing strong evidence for the effectiveness of the 2COOOL pipeline in real-world applications.
9. Experimental Results and Analysis
This section presents a comprehensive evaluation of the 2COOOL pipeline, examining both quantitative performance metrics and qualitative outcomes across detection and captioning tasks. The analysis provides insights into the system’s strengths, limitations, and practical utility for real-world deployment.
9.1 Detection Performance
The incident detection module demonstrates strong performance across multiple evaluation metrics, with the ensemble approach consistently outperforming individual models.
Table 9.1: Comparative Detection Performance Across Models
Model |
CV Accuracy |
Test Accuracy |
Precision (Incident) |
Recall (Incident) |
F1-Score (Incident) |
AUC-ROC |
Random Forest |
0.7625 ± 0.0729 |
0.7500 |
0.78 |
0.93 |
0.85 |
0.85 |
Gradient Boosting |
0.7750 ± 0.0500 |
0.8500 |
1.00 |
0.80 |
0.89 |
0.92 |
Logistic Regression |
0.7875 ± 0.0500 |
0.9000 |
1.00 |
0.87 |
0.93 |
0.95 |
SVC |
0.7375 ± 0.0468 |
0.7500 |
0.78 |
0.93 |
0.85 |
0.84 |
Ensemble (Voting) |
– |
0.9000 |
1.00 |
0.87 |
0.93 |
0.95 |
Key Observations:
· The Logistic Regression and Ensemble models achieved the highest test accuracy (0.90), demonstrating the effectiveness of our feature engineering approach for linear separation of incidents from normal driving.
· Gradient Boosting showed perfect precision (1.00) but lower recall (0.80), making it suitable for applications where false alarms must be minimized.
· The Ensemble approach successfully combined the strengths of individual models, achieving both high precision and recall while maintaining the best overall accuracy.
· All models showed strong AUC-ROC values (>0.84), indicating excellent separability between incident and non-incident classes across different probability thresholds.
The confusion matrix analysis (from classification reports in Table 1.0) reveals that most errors occurred in distinguishing between minor incidents (Severity 1) and normal driving, while severe incidents (Severity 3-5) were detected with near-perfect accuracy.
9.2 Caption Quality
The hybrid captioning approach demonstrated significant advantages over baseline methods across all automated evaluation metrics.
Table 9.2: Caption Quality Metrics Across Different Approaches
Method |
METEOR |
SPICE |
CiDER-D |
Human Rating (Factual) |
Human Rating (Fluency) |
Template-Only |
0.2850 |
0.1650 |
0.2450 |
3.2/5.0 |
2.8/5.0 |
Detection + Basic Template |
0.3520 |
0.1880 |
0.3010 |
3.8/5.0 |
3.1/5.0 |
Learned Captioner (Seq2Seq) |
0.4010 |
0.1950 |
0.2850 |
3.5/5.0 |
4.2/5.0 |
Hybrid (Our Method) |
0.4351 |
0.2230 |
0.3620 |
4.5/5.0 |
4.1/5.0 |
Analysis:
· Our Hybrid approach achieved the highest scores across all automated metrics, with particularly strong performance on CiDER-D (0.3620), indicating better alignment with the factual, safety-critical nature of incident descriptions.
· The Template-Only baseline performed poorly on fluency metrics, producing rigid and repetitive descriptions despite reasonable factual accuracy.
· The Learned Captioner showed good fluency (highest human fluency rating: 4.2/5.0) but suffered from factual errors and omissions, resulting in lower scores on factual metrics like CiDER-D and human factual ratings.
· The Detection + Basic Template approach demonstrated that even simple template filling based on detection outputs significantly improves over pure templates, but lacked the contextual richness of our full hybrid system.
The human evaluation results strongly correlated with our proposed CiDER-D metric (Pearson r=0.89 for factual correctness), validating its effectiveness as a domain-specific evaluation tool.
9.3 Correlation Analysis
We investigated the relationship between detection confidence and caption quality to understand how the system’s certainty about incidents affects descriptive output.
Detection Confidence vs. Caption Quality:
· Strong Positive Correlation (r=0.76) between incident probability scores and CiDER-D metrics for true positive detections
· High-confidence incidents (>0.8 probability) generated captions with average CiDER-D=0.41 ± 0.05
· Low-confidence incidents (0.5-0.8 probability) produced captions with average CiDER-D=0.32 ± 0.07
· False positives typically showed low caption quality (CiDER-D=0.18 ± 0.12), suggesting the system struggles to generate coherent descriptions when the visual evidence is ambiguous
Feature-Caption Alignment:
· Optical flow magnitude showed strong correlation with action verb selection in captions (e.g., high flow → “swerved”, “accelerated”)
· Edge density changes correlated with descriptive terms about vehicle deformation or environmental damage
· Object count consistency between detection and caption references was 92% for high-confidence incidents
These correlations suggest that the system maintains internal consistency between its visual understanding and linguistic output, particularly when the visual evidence is clear.
9.4 Qualitative Examples
Example 1: High-Quality Detection and Description
· Video Context: Highway driving, daytime, clear weather
· Incident: “vehicle hits ego-car” (Severity: 1)
· Generated Caption: “The ego vehicle is traveling on a highway during daytime with moderate traffic under clear conditions. Another vehicle collided with the ego car from the side during a lane change maneuver.”
· Detection Confidence: 0.94
· Metrics: CiDER-D=0.45, METEOR=0.52, SPICE=0.28
· Analysis: The description accurately captures the context, incident type, and specific dynamics while maintaining natural fluency.
Example 2: Medium Confidence with Minor Errors
· Video Context: Urban intersection, rainy conditions
· Incident: “pedestrian is crossing the street” (Severity: 0 – no collision)
· Generated Caption: “Driving on a city street in rainy weather, the ego car encounters heavy traffic flow during daytime. A pedestrian entered the crosswalk requiring emergency braking.”
· Detection Confidence: 0.67
· Metrics: CiDER-D=0.35, METEOR=0.41, SPICE=0.21
· Analysis: Correctly identifies the pedestrian action but overstates the vehicle response (“emergency braking” vs. actual moderate deceleration).
Example 3: Challenging Scenario
· Video Context: Low-light residential area, dusk
· Incident: “animal on the road” (Severity: 0)
· Generated Caption: “During dusk, the vehicle navigates through light traffic on a residential road with overcast visibility. An animal appeared on the road forcing evasive action.”
· Detection Confidence: 0.58
· Metrics: CiDER-D=0.29, METEOR=0.38, SPICE=0.19
· Analysis: The system correctly identifies the animal presence but struggles with precise classification (“animal” vs. specific “dog”) due to poor lighting conditions.
9.5 Error Analysis
Detection Errors:
1. False Negatives (12% of incidents):
o Primary cause: Subtle incidents with minimal motion signatures (e.g., slow-speed contacts, distant pedestrian interactions)
o Common in scenarios with complex backgrounds or occlusions
o Particularly challenging for “vehicle overtakes” and “pedestrian on the road” categories
2. False Positives (8% of non-incidents):
o Triggered by sudden illumination changes (tunnel entries, headlight glare)
o Camera vibrations from poor road surfaces
o Aggressive but normal driving maneuvers
Captioning Errors:
1. Factual Inaccuracies (15% of generated captions):
o Incorrect actor identification in crowded scenes
o Overstated severity of minor incidents
o Misattributed causation for complex multi-vehicle events
2. Linguistic Issues (10% of generated captions):
o Awkward phrasing in complex template combinations
o Inconsistent tense usage in sequential descriptions
o Redundant information in merged template segments
Systemic Limitations:
· Temporal Understanding: Difficulty in describing events that unfold over extended periods
· Causal Reasoning: Limited ability to infer chains of events or root causes
· Context Preservation: Challenges in maintaining consistent context across multiple related incidents in longer videos
The error analysis reveals that while the system performs well on clear, unambiguous incidents, there remains significant room for improvement in handling complex, subtle, or sequential events. Future work should focus on enhanced temporal modeling and more sophisticated causal reasoning capabilities.
Overall, the results demonstrate that the 2COOOL pipeline successfully achieves its dual objectives of reliable incident detection and coherent description generation, providing a solid foundation for practical deployment in road safety and autonomous vehicle applications.
- Deployment Considerations
The transition from research prototype to production-ready system requires careful attention to real-world operational constraints. This section addresses the practical challenges of deploying the 2COOOL pipeline in embedded automotive systems, roadside monitoring stations, and other edge computing environments, with particular focus on resource management, performance optimization, and compliance considerations.
10.1 On-Device Constraints
Deployment in automotive and edge environments imposes stringent hardware limitations that directly impact system architecture and performance characteristics.
Memory Footprint:
- Target Budget: <2GB RAM for entire pipeline operation
- Current Status: 6.2GB peak usage (development), requiring optimization for production
- Component Breakdown:
- Feature Extraction: 1.2GB (video decoding + intermediate frames)
- Model Inference: 0.8GB (ensemble models + CNN weights)
- Caption Generation: 0.1GB (template bank + language model)
- System Overhead: 0.1GB (OS + runtime)
Computational Requirements:
- CPU: Minimum 4 cores @ 2.0GHz for real-time processing at 15 FPS
- GPU: Optional integrated GPU (Intel UHD, NVIDIA Jetson) for CNN acceleration
- Storage: 500MB for model weights, templates, and temporary processing
Latency Budget:
- Real-time Processing: <100ms end-to-end latency for immediate incident response
- Near-real-time: 2-5 seconds for post-incident analysis and reporting
- Breakdown:
- Video decoding: 15ms
- Feature extraction: 45ms
- Model inference: 25ms
- Caption generation: 10ms
- System overhead: 5ms
Power Consumption:
- Target: <15W for continuous operation in vehicle environments
- Optimization: Dynamic frequency scaling based on processing load
- Sleep Modes: Low-power monitoring (0.5W) when no activity detected
10.2 MemoryManager and Resource Optimization
The MemoryManager class implements sophisticated strategies for adaptive resource management in constrained environments.
Adaptive Frame Rate Processing:
python
class AdaptiveMemoryManager(MemoryManager):
def __init__(self, memory_limit_gb=2):
super().__init__(memory_limit_gb)
self.quality_modes = {
‘high’: {‘frame_skip’: 2, ‘resolution’: (320, 240)},
‘medium’: {‘frame_skip’: 5, ‘resolution’: (240, 180)},
‘low’: {‘frame_skip’: 10, ‘resolution’: (160, 120)}
}
self.current_mode = ‘medium’
def adjust_processing_quality(self, available_memory_ratio):
if available_memory_ratio > 0.7:
self.current_mode = ‘high’
elif available_memory_ratio > 0.4:
self.current_mode = ‘medium’
else:
self.current_mode = ‘low’
Feature Caching Strategy:
- Short-term Cache: Keep recent feature vectors (last 30 seconds) for rapid re-analysis
- Selective Persistence: Store only high-confidence incident features for long-term retention
- Incremental Updates: Update statistical aggregates without storing full temporal sequences
Incremental Inference Pipeline:
python
def incremental_inference(self, video_stream, chunk_size=64):
“””Process video in chunks to minimize memory footprint”””
results = []
for chunk in self.stream_processor.chunk_video(video_stream, chunk_size):
# Process chunk with minimal state carryover
chunk_features = self.extract_chunk_features(chunk)
chunk_prediction = self.lightweight_detector.predict(chunk_features)
if self.needs_full_analysis(chunk_prediction):
# Only run full pipeline on high-probability segments
full_analysis = self.full_pipeline.process_chunk(chunk)
results.append(full_analysis)
else:
results.append(chunk_prediction)
self.memory_manager.force_cleanup()
return self.merge_incremental_results(results)
Model Optimization Techniques:
- Quantization: FP32 → INT8 conversion for 4x memory reduction, 2-3x speedup
- Pruning: Remove 50% of low-impact weights with <1% accuracy loss
- Knowledge Distillation: Train smaller student models to mimic ensemble behavior
- Model Segmentation: Split large models across processing stages with intermediate persistence
10.3 Privacy and Legal Considerations
Deployment in real-world environments necessitates careful attention to privacy protection and regulatory compliance, particularly given the sensitive nature of visual data from public spaces.
Personally Identifiable Information (PII) Handling:
- Real-time Anonymization:
python
def anonymize_frame(self, frame):
# Blur faces with adaptive kernel based on detection confidence
faces = self.face_detector.detect(frame)
for (x, y, w, h) in faces:
face_roi = frame[y:y+h, x:x+w]
blurred_face = cv2.GaussianBlur(face_roi, (23, 23), 30)
frame[y:y+h, x:x+w] = blurred_face
# Obscure license plates
plates = self.plate_detector.detect(frame)
for plate in plates:
frame = self.obscure_region(frame, plate.bbox)
return frame
Data Retention Policies:
- Incident-Only Storage: Retain only video segments with detected incidents (5 seconds pre/post event)
- Automated Deletion: Remove non-incident footage after 24-72 hours based on jurisdiction
- Tiered Storage:
- Edge: Raw video (24 hours)
- Local: Features + anonymized clips (30 days)
- Cloud: Incident reports + metrics (2+ years for legal compliance)
Regulatory Compliance:
- GDPR Compliance: Implement right-to-erasure for captured data of EU citizens
- CCPA Compliance: Provide opt-out mechanisms for California residents
- Local Regulations: Adapt to jurisdiction-specific requirements for dashcam usage
- Insurance Standards: Align with industry guidelines for incident data handling
Security Measures:
- Data Encryption: AES-256 encryption for stored video and transmitted data
- Access Control: Role-based access to incident data and system configuration
- Audit Logging: Comprehensive logging of data access and processing activities
- Secure Deletion: Cryptographic erasure of sensitive data upon retention expiry
Ethical Deployment Guidelines:
- Transparency: Clear signage when dashcams are deployed in monitoring capacity
- Purpose Limitation: Use collected data only for declared safety and analysis purposes
- Minimization: Collect only necessary data for incident analysis
- Accountability: Regular audits of data handling practices and privacy compliance
Operational Considerations:
- Fail-Safe Operation: System continues basic recording even if AI components fail
- Graceful Degradation: Maintain core functionality under resource constraints
- Update Mechanisms: Secure over-the-air updates for model improvements and security patches
- Diagnostic Capabilities: Remote monitoring of system health and performance metrics
The deployment considerations outlined here ensure that the 2COOOL pipeline can operate effectively within the practical constraints of real-world environments while maintaining compliance with privacy regulations and ethical standards. This balance of performance, efficiency, and responsibility is essential for widespread adoption in safety-critical automotive and surveillance applications. Future work will focus on further optimization of the memory footprint and development of more sophisticated privacy-preserving techniques to enable broader deployment across diverse operational scenarios.
11. Discussion and Limitations
The experimental results demonstrate that the 2COOOL pipeline represents a significant step toward automated incident analysis, yet careful consideration of its limitations and potential risks is essential for responsible deployment and future improvement. This section critically examines the system’s generalizability, data dependencies, evaluation challenges, and ethical implications.
11.1 Generalizability and Robustness
While the pipeline shows strong performance on the curated dataset, several factors may impact its generalizability across diverse real-world scenarios:
Geographical and Cultural Variations:
- Traffic Patterns: Models trained primarily on urban driving may underperform in rural settings with different road geometries, wildlife patterns, and driving behaviors
- Vehicle Types: Performance may degrade in regions with predominance of vehicle types underrepresented in training (e.g., tuk-tuks, rickshaws, animal-drawn carts)
- Road Infrastructure: Variations in signage, lane markings, and intersection designs across countries could affect feature extraction reliability
Environmental Conditions:
- Lighting Challenges: The system shows reduced performance in extreme lighting conditions:
- Night driving with poor illumination
- Rapid transitions (tunnel entries/exits)
- Seasonal variations (snow, heavy rain, fog)
- Weather Robustness: While basic weather conditions are handled, severe weather events (hail, torrential rain) can overwhelm the optical flow and edge detection algorithms
- Camera Artifacts: Lens flare, water droplets, dirt accumulation, and windshield reflections introduce noise not fully addressed in current implementation
Hardware and Installation Variables:
- Camera Mount Variations: Different mounting positions (windshield, dashboard, rear-view mirror) affect perspective and motion interpretation
- Camera Quality: Resolution, frame rate, and sensor quality variations across devices impact feature extraction consistency
- Vehicle-Specific Factors: Vibration patterns, suspension characteristics, and windshield angles introduce unmodeled variability
The current evaluation primarily reflects performance under controlled conditions, and extensive field testing across diverse environments is necessary to fully characterize real-world robustness.
11.2 Dataset Limitations and Biases
The foundation of any machine learning system is its training data, and several limitations in our dataset warrant attention:
Size and Diversity Concerns:
- Limited Scale: 100 videos, while sufficient for initial validation, is inadequate for capturing the long tail of rare but critical incident types
- Class Imbalance: The 75/25 incident/non-incident ratio in our dataset (Table 1.0) doesn’t reflect real-world distributions where incidents are extremely rare events
- Geographic Bias: Data sourced from limited geographical regions may not represent global driving conditions and behaviors
- Temporal Coverage: Inadequate representation of all seasons, times of day, and weather conditions
Annotation Quality and Consistency:
- Subjective Severity Ratings: The 7-level severity scale (Section 3.2) involves human judgment with inherent subjectivity
- Template-Induced Bias: The use of template-based annotations for training evaluation may artificially inflate performance on similar template-based generation
- Cultural Context: Descriptions may reflect cultural assumptions about “normal” driving behavior that don’t generalize universally
Recommended Mitigations:
- Active Learning: Prioritize collection of edge cases and underrepresented scenarios
- Synthetic Data Generation: Use simulation and data augmentation to expand diversity
- Federated Learning: Aggregate learning across distributed deployments while preserving privacy
- Continuous Evaluation: Implement ongoing performance monitoring in deployment environments
11.3 Evaluation Metric Limitations
While our proposed CiDER-D metric shows promise, all automated evaluation methods for generated text have inherent limitations:
Short-Text Evaluation Challenges:
- Limited Context: With only 5-15 words, statistical metrics have insufficient signal for robust evaluation
- Synonym Sensitivity: “Car,” “vehicle,” and “automobile” may be functionally equivalent in incident reports but treated as errors by n-gram metrics
- Factual Precision vs. Fluency Trade-off: Metrics struggle to balance grammatical correctness against factual accuracy
Domain-Specific Biases:
- Safety-Term Over-emphasis: CiDER-D’s boosting of safety-critical terms may undervalue syntactically complex but factually equivalent phrasing
- Temporal Understanding Gap: Current metrics cannot evaluate whether descriptions correctly capture event sequences or causal relationships
- Context Preservation: Inability to measure consistency across multiple descriptions from the same video segment
Human Evaluation Constraints:
- Scalability: Expert evaluation is time-consuming and expensive, limiting dataset size
- Subjectivity: Inter-rater reliability, while measured, remains a concern for nuanced judgments
- Fatigue Effects: Rating quality degrades with large evaluation batches
The moderate correlation between automated metrics and human judgment (Section 9.2) suggests that while current metrics provide useful guidance, they cannot replace human evaluation for final system validation.
11.4 Ethical Considerations and Potential Risks
The deployment of automated incident analysis systems carries significant ethical responsibilities and potential misuse scenarios:
Misreporting and False Positives/Negatives:
- Safety Impacts: Missed incidents (false negatives) could delay emergency response, while false alarms (false positives) may desensitize operators to real threats
- Financial Consequences: Incorrect incident reports could lead to unjustified insurance claims, legal liabilities, or unnecessary vehicle inspections
- Reputational Damage: Consistent errors could undermine trust in automated safety systems
Downstream Misuse Scenarios:
- Surveillance Creep: Technology intended for safety could be repurposed for employee monitoring, traffic enforcement, or other privacy-invasive applications
- Biased Enforcement: If deployment patterns correlate with demographic factors, the system could disproportionately impact certain communities
- Data Exploitation: Incident data could be used for purposes beyond safety, such as marketing, insurance premium adjustments, or litigation
Mitigation Strategies:
- Transparent Operation: Clear documentation of system capabilities, limitations, and error rates
- Human-in-the-Loop: Maintain human oversight for high-stakes decisions and system outputs
- Regular Auditing: Independent evaluation of system performance across different demographics and environments
- Purpose Limitation: Technical and contractual restrictions on data usage beyond safety applications
- Error Analysis Protocols: Systematic investigation of failure modes and continuous improvement cycles
Broader Societal Impacts:
- Workforce Effects: Potential displacement of human traffic monitors and claims adjusters
- Legal Evidence Standards: Challenges in establishing the reliability of automated systems for legal proceedings
- Insurance Model Disruption: Shift from traditional claims processes to automated incident reporting
The limitations identified here are not unique to our system but represent broader challenges in deploying AI for safety-critical applications. Addressing these concerns requires ongoing collaboration between researchers, industry stakeholders, regulators, and the public to ensure that technological advancement aligns with societal values and safety objectives.
Future work should prioritize expanding dataset diversity, developing more nuanced evaluation frameworks, and establishing clear ethical guidelines for deployment. By acknowledging these limitations and proactively addressing them, we can work toward systems that not only perform well in controlled evaluations but also operate reliably and responsibly in the complex, unpredictable real world.
12. Conclusion and Future Work
This research has presented the 2COOOL pipeline, a comprehensive framework for automated incident detection and description from dashcam footage. Through careful design and extensive evaluation, we have demonstrated that a hybrid approach combining classical computer vision with modern machine learning can achieve robust performance while maintaining computational efficiency suitable for edge deployment.
12.1 Summary of Contributions and Empirical Takeaways
The primary contributions of this work can be summarized as follows:
Technical Contributions:
1. A Novel Hybrid Pipeline: We developed an integrated system that couples efficient handcrafted feature extraction with ensemble classification and template-augmented natural language generation, achieving a balance between performance, interpretability, and computational efficiency that is often missing in purely deep learning-based approaches.
2. CiDER-D Metric: We introduced a domain-adapted evaluation metric specifically designed for short, factual incident descriptions, demonstrating better alignment with human judgment than existing captioning metrics through its TF-IDF weighting of safety-critical terms and length normalization.
3. Resource-Aware Architecture: The implementation of the MemoryManager class and adaptive processing strategies provides a blueprint for deploying complex AI pipelines in constrained environments, addressing a critical gap between research prototypes and production systems.
Empirical Findings:
· The ensemble of classical classifiers achieved 0.90 test accuracy for incident detection, demonstrating that carefully engineered features can compete with more complex deep learning approaches while offering greater transparency and efficiency.
· Our hybrid captioning approach outperformed all baselines, achieving CiDER-D=0.3620, METEOR=0.4351, and SPICE=0.2230, while receiving the highest human ratings for factual correctness (4.5/5.0).
· The strong correlation (r=0.76) between detection confidence and caption quality indicates internal consistency in the system’s understanding and description capabilities.
· The pipeline successfully operated within an 8GB memory constraint while processing 100 videos, with peak usage of 6.2GB, demonstrating feasibility for edge deployment.
These results validate our core hypothesis that a modular, interpretable approach can effectively address the dual challenges of incident detection and description while maintaining the efficiency required for real-world deployment.
12.2 Future Directions
While the current pipeline shows promising results, several exciting directions emerge for future research and development:
Human-in-the-Loop Labeling and Active Learning:
· Interactive Annotation Framework: Develop tools that allow human annotators to efficiently correct and refine system outputs, creating a virtuous cycle of improvement
· Uncertainty-Based Sampling: Prioritize labeling of examples where the system shows low confidence or high disagreement between ensemble members
· Cross-Domain Adaptation: Leverage human feedback to rapidly adapt models to new geographical regions or environmental conditions
Multimodal Transformer Architectures:
· Unified Encoder-Decoder Framework: Explore end-to-end transformer models that jointly process visual and textual information, potentially improving contextual understanding
· Temporal Attention Mechanisms: Develop specialized attention patterns for capturing long-range dependencies in driving scenarios
· Efficient Variants: Investigate distilled transformer models that maintain performance while reducing computational requirements for edge deployment
Multimodal Pre-training Strategies:
· Self-Supervised Learning: Leverage large-scale unlabeled dashcam footage for pre-training using objectives like temporal ordering, frame reconstruction, and contrastive learning
· Cross-Modal Alignment: Pre-train models to align visual sequences with textual descriptions from diverse sources, improving generalization
· Domain-Specific Foundation Models: Develop pre-trained models specifically for traffic and driving scenarios, analogous to CLIP but optimized for temporal understanding
Richer Explanation Modules:
· Causal Reasoning: Extend beyond descriptive captions to include causal explanations of why incidents occurred and how they might have been prevented
· Counterfactual Generation: Produce alternative scenarios describing what would have happened under different conditions or actions
· Uncertainty Quantification: Provide confidence intervals and alternative interpretations for ambiguous situations
· Visual Grounding: Generate descriptions with explicit references to spatial regions in the video, enhancing interpretability
Additional Promising Directions:
· Federated Learning: Enable collaborative model improvement across multiple deployment sites while preserving data privacy
· Lifelong Learning: Develop mechanisms for continuous model adaptation to new incident types and driving conditions without catastrophic forgetting
· Multi-Camera Fusion: Extend the pipeline to leverage multiple camera views (dashcam, rear-view, side mirrors) for comprehensive scene understanding
· Predictive Capabilities: Move beyond incident detection to anticipation and early warning generation
Broader Impact Considerations:
· Standardization Efforts: Collaborate with industry partners to establish benchmarks, evaluation protocols, and safety standards for automated incident analysis systems
· Policy Engagement: Work with regulators to develop appropriate frameworks for the use of automated systems in insurance, law enforcement, and safety applications
· Public Awareness: Create educational materials to help stakeholders understand the capabilities and limitations of automated incident analysis
The 2COOOL pipeline represents a significant step toward automated understanding of traffic incidents, but it is merely the beginning of a broader research trajectory. By building on the foundations established here and pursuing the directions outlined above, we can work toward systems that not only detect and describe incidents but ultimately help prevent them, contributing to the overarching goal of improved road safety for all.
The integration of human expertise with automated analysis, the development of more sophisticated multimodal understanding, and the creation of systems that can explain their reasoning in human-understandable terms represent the next frontier in this important domain. We hope this work inspires further research at the intersection of computer vision, natural language processing, and transportation safety.
REFERENCES
Original Dataset provided by:
@article{alshami20252coool, title = {2COOOL: 2nd Workshop on the Challenge Of Out-Of-Label Hazards in Autonomous Driving}, author = {AlShami, Ali K, Rabinowitz, Ryan, Shoman, Maged, Fang, Jianwu, Picek, Lukas, Lo, Shao-Yuan, Cruz, Steve, Lam, Khang Nhut, Kamod, Nachiket, Li, Lei-Lei, others}, journal = {arXiv preprint arXiv:2508.21080}, year = {2025} } —————————————————————————————————————- @article{alshami2024coool, title = {COOOL: Challenge of Out-of-Label — A Novel Benchmark for Autonomous Driving}, author = {AlShami, Ali K, Kalita, Ananya, Rabinowitz, Ryan, Lam, Khang, Bezbarua, Rishabh, Boult, Terrance, and Kalita, Jugal}, journal = {arXiv preprint arXiv:2412.05462}, year = {2024} } . 2COOOL. https://kaggle.com/competitions/2coool, 2025. Kaggle.
| S/N | References |
| [1] | Agarwal, L., & Verma, B. (2025). Towards Explainable AI: Multi-Modal Transformer for Video-based Image Description Generation. arXiv preprint arXiv:2504.16788. |
| [2] | Areerob, K., Nguyen, V. Q., Li, X., Inadomi, S., Shimada, T., Kanasaki, H., … & Okatani, T. (2025). Multimodal artificial intelligence approaches using large language models for expert‐level landslide image analysis. Computer‐Aided Civil and Infrastructure Engineering. |
| [3] | Biswas, S., Khan, M. N. H., & Islam, B. (2025). RAVEN: Query-Guided Representation Alignment for Question Answering over Audio, Video, Embedded Sensors, and Natural Language. arXiv preprint arXiv:2505.17114. |
| [4] | Chowdhury, M. D., & Hossain, M. (2025). Design and Application of Multimodal Large Language Model Based System for End-to-End Automation of Accident Dataset Generation. arXiv preprint arXiv:2505.00015. |
| [5] | Chen, L., Qian, Z., Li, P., & Zhu, Q. (2025). Multimodal Fake News Video Explanation: Dataset, Analysis and Evaluation. arXiv preprint arXiv:2501.08514. |
| [6] | Chen, X., Cumin, J., Ramparany, F., & Vaufreydaz, D. (2025). MuRAL: A Multi-Resident Ambient Sensor Dataset Annotated with Natural Language for Activities of Daily Living. arXiv preprint arXiv:2504.20505. |
| [7] | Deshmukh, S., Han, S., Singh, R., & Raj, B. (2025). ADIFF: Explaining audio difference using natural language. arXiv preprint arXiv:2502.04476. |
| [8] | Dey, A., Bothera, A., Sarikonda, S., Aryan, R., Podishetty, S. K., Havalgi, A., … & Singh, G. (2025, July). Multimodal Event Detection: Current Approaches and Defining the New Playground Through LLMs and VLMs. In International Conference on Applications of Natural Language to Information Systems (pp. 457-471). Cham: Springer Nature Switzerland. |
| [9] | Dong, X., Peng, B., Ma, H., Wang, Y., Dong, Z., Hu, F., & Wang, X. (2025). Leadqa: Llm-driven context-aware temporal grounding for video question answering. arXiv preprint arXiv:2507.14784. |
| [10] | Faheem, M., Awais, M., Iqbal, A., & Zia, H. (2025). Enhancing IT incident management with natural language processing and predictive analytics. International Journal of Science and Research Archive, 15(3), 224-237. |
| [11] | Gao, Y., Piccinini, M., Zhang, Y., Wang, D., Moller, K., Brusnicki, R., … & Betz, J. (2025). Foundation Models in Autonomous Driving: A Survey on Scenario Generation and Scenario Analysis. arXiv preprint arXiv:2506.11526. |
| [12] | Hagen, D., Schwarz, K., Creutzburg, R. M., & Gaeva, D. V. (2025, May). AI-based tools for efficient event network communication: transformation and potentials. In Multimodal Image Exploitation and Learning 2025 (Vol. 13457, pp. 119-127). SPIE. |
| [13] | Jaradat, S., Elhenawy, M., Ashqar, H. I., Paz, A., & Nayak, R. (2025). Leveraging deep learning and multimodal large language models for near-miss detection using crowdsourced videos. IEEE Open Journal of the Computer Society. |
| [14] | Jaradat, S. (2025). AI and Big Data for Intelligent Traffic Safety: A Multimodal Approach Using Deep Learning and Large Language Models (Doctoral dissertation, Queensland University of Technology). |
| [15] | Jaradat, S., Elhenawy, M., Nayak, R., Paz, A., Ashqar, H. I., & Glaser, S. (2025). Multimodal Data Fusion for Tabular and Textual Data: Zero-Shot, Few-Shot, and Fine-Tuning of Generative Pre-Trained Transformer Models. AI, 6(4), 72. |
| [16] | Karim, M. M., Shi, Y., Zhang, S., Wang, B., Nasri, M., & Wang, Y. (2025). Large Language Models and Their Applications in Roadway Safety and Mobility Enhancement: A Comprehensive Review. arXiv preprint arXiv:2506.06301. |
| [17] | Kong, Q., Zhang, Y., Liu, Y., Tong, P., Liu, E., & Zhou, F. (2025). Language-tpp: Integrating temporal point processes with language models for event analysis. arXiv preprint arXiv:2502.07139. |
| [18] | Kuang, S., Liu, Y., Qu, X., & Wei, Y. (2025). Traffic-IT: Enhancing traffic scene understanding for multimodal large language models. Transportation Research Part C: Emerging Technologies, 180, 105325. |
| [19] | Kuang, J., Shen, Y., Xie, J., Luo, H., Xu, Z., Li, R., … & Han, Y. (2025). Natural language understanding and inference with mllm in visual question answering: A survey. ACM Computing Surveys, 57(8), 1-36. |
| [20] | Lai, C., & Qiu, S. (2025). MKER: multi-modal knowledge extraction and reasoning for future event prediction. Complex & Intelligent Systems, 11(2), 138. |
| [21] | Lei, P., Song, J., Hao, Y., Chen, T., Zhang, Y., JIA, L., & Li, Y. ITFormer: Bridging Time Series and Natural Language for Multi-Modal QA with Large-Scale Multitask Dataset. In Forty-second International Conference on Machine Learning. |
| [22] | Li, Z., Ma, C., Zhou, Y., Lord, D., & Zhang, Y. (2025). Leveraging Textual Description and Structured Data for Estimating Crash Risks of Traffic Violation: A Multimodal Learning Approach. IEEE Transactions on Intelligent Transportation Systems. |
| [23] | Li, M., Ding, W., Lin, H., Lyu, Y., Yao, Y., Zhang, Y., & Zhao, D. (2025). CrashAgent: Crash Scenario Generation via Multi-modal Reasoning. arXiv preprint arXiv:2505.18341. |
| [24] | Li, C., Zhou, K., Liu, T., Wang, Y., Zhuang, M., Gao, H. A., … & Zhao, H. (2025). Avd2: Accident video diffusion for accident video description. arXiv preprint arXiv:2502.14801. |
| [25] | Li, P., Lu, Y., Song, P., Li, W., Yao, H., & Xiong, H. (2025). Eventvl: Understand event streams via multimodal large language model. arXiv preprint arXiv:2501.13707. |
| [26] | Li, M., & Zhou, Z. (2025). Multimodal Context Fusion Based Dense Video Captioning Algorithm. Engineering Letters, 33(4). |
| [27] | Liu, S., Li, J., Zhao, G., Zhang, Y., Meng, X., Yu, F. R., … & Li, M. (2025). Eventgpt: Event stream understanding with multimodal large language models. In Proceedings of the Computer Vision and Pattern Recognition Conference (pp. 29139-29149). |
| [28] | Loumachi, F. Y., Ghanem, M. C., & Ferrag, M. A. (2025). Advancing cyber incident timeline analysis through retrieval-augmented generation and large language models. Computers, 14(67), 1-42. |
| [29] | Lu, H., & Du, Z. (2025, February). Dense video event semantic annotation based on multimodal features. In Sixteenth International Conference on Graphics and Image Processing (ICGIP 2024) (Vol. 13539, pp. 430-440). SPIE. |
| [30] | Masukawa, R., Yun, S., Jeong, S., Huang, W., Ni, Y., Bryant, I., … & Imani, M. (2025). PacketCLIP: Multi-Modal Embedding of Network Traffic and Language for Cybersecurity Reasoning. arXiv preprint arXiv:2503.03747. |
| [31] | Nanyonga, A., Joiner, K., Turhan, U., & Wild, G. (2025). Natural Language Processing for Aviation Safety: Predicting Injury Levels from Incident Reports in Australia. Modelling, 6(2), 40. |
| [32] | Nanyonga, A., Wasswa, H., Joiner, K., Turhan, U., & Wild, G. (2025). A Multi-Head Attention-Based Transformer Model for Predicting Causes in Aviation Incidents. Modelling, 6(2), 27. |
| [33] | Nguyen, H., Nguyen, P. T., Tran, T. P., Nguyen, M. Q., Nguyen, T. V., Tran, M. T., & Le, T. N. (2025). OpenEvents V1: Large-Scale Benchmark Dataset for Multimodal Event Grounding. arXiv preprint arXiv:2506.18372. |
| [34] | PAULRAJ, N. J. (2025). Natural Language Processing on Clinical Notes: Advanced Techniques for Risk Prediction and Summarization. Journal of Computer Science and Technology Studies, 7(3), 494-502. |
| [35] | Peralta, A., Olivas, J. A., & Navarro-Illana, P. (2025). A Fuzzy Logic Framework for Text-Based Incident Prioritization: Mathematical Modeling and Case Study Evaluation. Mathematics, 13(12), 2014. |
| [36] | Priyanka, P., & Balachander, T. (2025, May). Multimodal Fusion for Coherent Description Generation: A System Integrating NLP, Computer Vision, and Speech Recognition. In 2025 International Conference on Computational Robotics, Testing and Engineering Evaluation (ICCRTEE) (pp. 1-6). IEEE. |
| [37] | Quinlan, P., Li, Q., & Zhu, X. (2025). Chat-TS: Enhancing Multi-Modal Reasoning Over Time-Series and Natural Language Data. arXiv preprint arXiv:2503.10883. |
| [38] | Qureshi, F., & Hashmi, A. (2025). Cross-Modal Transformer Networks for Dynamic Video Moment Detection. |
| [39] | Rafiq, M., Sung, M., Rafiq, G., & Choi, G. S. (2025). Camscribe: Enhanced Dashcam Video Descriptions Through Multimodal Spatiotemporal and Object Detection for Autonomous Vehicles. IEEE Access. |
| [40] | Ren, T., Zhang, Z., Jia, B., & Zhang, S. (2025). Retrieval-Augmented Generation-aided causal identification of aviation accidents: A large language model methodology. Expert Systems with Applications, 278, 127306. |
| [41] | Shomee, H. H., Wang, Z., Ravi, S. N., & Medya, S. (2025, July). A survey on patent analysis: From nlp to multimodal ai. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 8545-8561). |
| [42] | Skender, I., Tong, K., Solmaz, S., & Watzenig, D. (2025). Investigating Traffic Accident Detection Using Multimodal Large Language Models. arXiv preprint arXiv:2509.19096. |
| [43] | Sun, Y., Luo, Y., Wen, X., Yuan, Y., Nie, X., Zhang, S., … & Luo, X. (2025). TrioXpert: An automated incident management framework for microservice system. arXiv preprint arXiv:2506.10043. |
| [44] | Surikuchi, A. K., Fernández, R., & Pezzelle, S. (2025). Natural Language Generation from Visual Events: Challenges and Future Directions. arXiv preprint arXiv:2502.13034. |
| [45] | Qasim, I., Horsch, A., & Prasad, D. (2025). Dense video captioning: A survey of techniques, datasets and evaluation protocols. ACM Computing Surveys, 57(6), 1-36. |
| [46] | Tami, M. A., Elhenawy, M., & Ashqar, H. I. (2025). Multimodal Large Language Models for Enhanced Traffic Safety: A Comprehensive Review and Future Trends. arXiv preprint arXiv:2504.16134. |
| [47] | Tariq, S., Woo, S. S., Singh, P., Irmalasari, I., Gupta, S., & Gupta, D. (2025). From Prediction to Explanation: Multimodal, Explainable, and Interactive Deepfake Detection Framework for Non-Expert Users. arXiv preprint arXiv:2508.07596. |
| [48] | Tran, T. P., Nguyen, M. Q., Tran, M. T., Nguyen, T. V., Do, T. L., Ly, D. N., … & Le, T. N. (2025). Event-Enriched Image Analysis Grand Challenge at ACM Multimedia 2025. arXiv preprint arXiv:2508.18904. |
| [49] | Tran, Q. L., Pham, N. N. D., Truong, Q. T., Nguyen, M. H., Le, H. C., Vu, D. K., … & Gurrin, C. (2025, June). A RAG Approach for Multi-Modal Open-ended Lifelog Question-Answering. In Proceedings of the 2025 International Conference on Multimedia Retrieval (pp. 1303-1312). |
| [50] | Wang, Q., Jiang, L., Ma, L., Jiang, H., Hu, X., & Jiang, S. (2025). Multimodal representation reconstruction for video localization with natural language. Multimedia Tools and Applications, 1-16. |
| [51] | Wang, Y., Lei, P., Song, J., Hao, Y., Chen, T., Zhang, Y., … & Wei, Z. (2025). ITFormer: Bridging Time Series and Natural Language for Multi-Modal QA with Large-Scale Multitask Dataset. arXiv preprint arXiv:2506.20093. |
| [52] | Wang, Y., & Birman, K. P. (2025, March). Diagnosing and Resolving Cloud Platform Instability with Multi-modal RAG LLMs. In Proceedings of the 5th Workshop on Machine Learning and Systems (pp. 139-147). |
| [53] | Wang, Y., Luo, H., & Fang, W. (2025). An integrated approach for automatic safety inspection in construction: Domain knowledge with multimodal large language model. Advanced Engineering Informatics, 65, 103246. |
| [54] | Wang, Y., Zhou, Y., Zhong, M., Mei, Y., Fujita, H., & Aljuaid, H. (2025). A Multimodal Traffic Scene Understanding Model Integrated with Optical Flow Maps. Neurocomputing, 130838. |
| [55] | Wei, H., Wu, B., Wang, C., Su, G., & Zhou, T. (2025, June). Demonstration Meets Typed Events: Type Specific Video Semantic Role Labeling via Multimodal Prompting and Retrieval. In Proceedings of the 2025 International Conference on Multimedia Retrieval (pp. 1461-1469). |
| [56] | Zhang, R., Wang, B., Zhang, J., Bian, Z., Feng, C., & Ozbay, K. (2025). When language and vision meet road safety: leveraging multimodal large language models for video-based traffic accident analysis. Accident Analysis & Prevention, 219, 108077. |
| [57] | Zhang, Y., Zhao, X., Ma, Y., Ma, H., Guan, Y., Yang, G., … & Wang, X. (2025). MM-AttacKG: A Multimodal Approach to Attack Graph Construction with Large Language Models. arXiv preprint arXiv:2506.16968. |
| [58] | Zhao, X., Li, C., Yang, J., Gu, X., Li, B., Wang, Y., … & Yu, W. (2025). Diagnostic report generation for macular diseases by natural language processing algorithms. British Journal of Ophthalmology. |
| [59] | Zhen, H., & Yang, J. J. (2025). CrashSage: A Large Language Model-Centered Framework for Contextual and Interpretable Traffic Crash Analysis. arXiv preprint arXiv:2505.07853. |